DeepSeek (딥시크) R1 | 강화 학습으로 진화하는 AI의 추론 능력
여러분은 AI가 실제로 '생각'할 수 있다고 상상해보신 적 있나요? DeepSeek-R1은 바로 그 상상을 현실로 만든 혁신적인 AI 모델입니다. 특히 주목할 만한 점은, OpenAI의 최신 추론 모델 o1 대비 10배 이상의 비용 효율화를 달성했다는 것입니다. 이는 AI 업계에 새로운 이정표를 제시했다는 평가를 받고 있죠. 오늘은 강화 학습을 통해 한 단계 진화하면서도 놀라운 비용 효율성을 실현한 DeepSeek-R1의 혁신적인 능력에 대해 자세히 알아보겠습니다.
DeepSeek-R1이란 무엇인가?
DeepSeek-R1은 기존 AI 모델들과는 완전히 다른 접근 방식을 택했습니다. 일반적인 지도학습 대신, 순수 강화 학습을 통해 개발된 이 모델은 마치 인간처럼 '시행착오'를 통해 학습하는 특별한 AI입니다.
DeepSeek-R1은 크게 두 가지 버전으로 나뉩니다:
- DeepSeek-R1-Zero: 지도학습 없이 순수 강화 학습으로만 개발된 모델
- DeepSeek-R1: Cold Start 데이터를 활용해 언어 능력을 보완한 개선 모델
DeepSeek-R1의 혁신적인 학습 방식
강화 학습의 새로운 패러다임
DeepSeek-R1이 도입한 강화 학습 방식은 ��기존 AI 학습법과는 확연히 다릅니다. 이 모델은 Group Relative Policy Optimization(GRPO)이라는 특별한 방식을 사용해 더욱 효율적으로 학습합니다.
주요 특징을 살펴보면:
- 비판자 모델을 생략해 학습 비용 대폭 절감
- 정확도와 형식을 동시에 고려하는 이중 보상 체계
- Cold Start 데이터를 활용한 단계적 학습 방식
지식 증류로 실현한 효율성
DeepSeek-R1의 또 다른 혁신은 '지식 증류' 기술의 도입입니다. 거대 모델의 지식을 작은 모델로 효과적으로 전달하는 이 기술 덕분에, 1.5B에서 70B 파라미터에 이르는 다양한 크기의 모델들이 모두 뛰어난 성능을 보여줍니다.
놀라운 성능과 실제 평가 결과
DeepSeek-R1의 성능은 실제 벤치마크 테스트에서도 입증되었습니다. 특히, OpenAI의 최신 모델과 비교했을 때 대부분의 분야에서 대등하거나 더 나은 성능을 보여주고 있습니다.
주요 벤치마크 성능 비교표
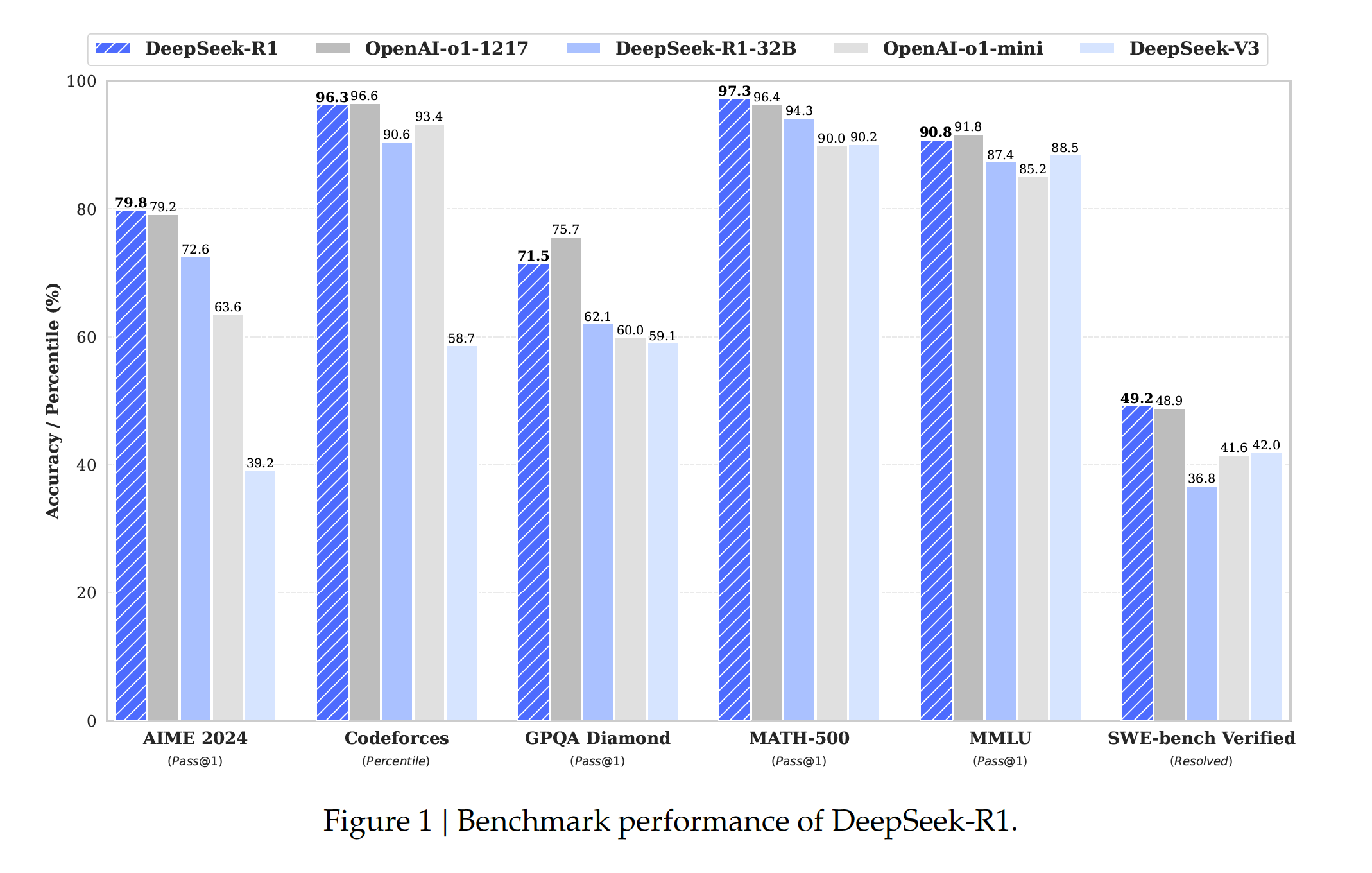
| 평가 분야 | 평가 지표 | OpenAI-o1 | DeepSeek-R1 | 성능 차이 |
|---|---|---|---|---|
| 수학 능력 | AIME 2024 | 79.2% | 79.8% | +0.6% |
| 고급 수학 | MATH-500 | 96.4% | 97.3% | +0.9% |
| 코딩 능력 | Codeforces | 96.6% | 96.3% | -0.3% |
| 일반 지식 | GPQA Diamond | 75.7% | 71.5% | -4.2% |
| 전문 지식 | MMLU | 91.8% | 90.8% | -1.0% |
*굵은 글씨는 각 분야별 최고 성능을 나타냅니다.
성능 분석 및 의의
이러한 벤치마크 결과가 특별히 주목받는 이유는 다음과 같습니다:
- 수학 분야 우수성
- AIME와 MATH-500에서 최고 성능 달성
- 복잡한 수학적 추론 능력 입증
- 비용 대비 효율성
- OpenAI 모델 대비 1/10 수준의 비용으로 동등한 성능 실현
- 실용적 활용 가능성 증가
현재의 한계와 미래 전망
극복해야 할 과제들
물론 DeepSeek-R1에도 개선이 필요한 부분들이 있습니다:
- Prompt 민감성 문제
- Few-shot 프롬프팅에서 성능 저하 발생
- 입력 형식에 따른 결과 편차 존재
- 다국어 지원의 한계
- 영어와 중국어 외 언어에서 성능 저하
- 문화적 맥락 이해 부족
- 소프트웨어 개발 분야의 제한
- 복잡한 시스템 설계에서 한계 노출
- 코드 최적화 능력 개선 필요
밝은 미래를 향한 발걸음
이러한 한계에도 불구하고, DeepSeek-R1은 AI 발전의 새로운 이정표를 제시했습니다. 앞으로의 발전 방향은 다음과 같습니다:
- 프롬프트 엔지니어링 최적화
- 다양한 입력 형식 수용력 강화
- 맥락 이해 능력 개선
- 다국어 능력 확장
- 다양한 언어 데이터 학습
- 문화적 맥락 이해도 향상
- 소프트웨어 개발 능력 강화
- 시스템 설계 능력 보완
- 코드 최적화 기술 향상
AI의 새로운 지평
DeepSeek-R1은 단순한 AI 모델이 아닌, 인공지능의 새로�운 패러다임을 제시하는 혁신적인 시도입니다. 강화 학습을 통한 추론 능력의 향상, 지식 증류를 통한 효율성 개선 등 DeepSeek-R1이 보여준 혁신은 앞으로 AI 기술 발전의 새로운 기준이 될 것입니다.
우리는 DeepSeek-R1을 통해 AI가 단순한 패턴 학습을 넘어, 진정한 '사고'와 '추론'이 가능한 단계로 발전할 수 있다는 것을 확인했습니다. 더욱이 이러한 발전이 비용 효율적으로 이루어질 수 있다는 점은 AI 기술의 대중화 가능성을 한층 높여주고 있습니다.
참고 문헌
본 글은 다음 논문을 바탕으로 작성되었습니다:
Guo, D., Yang, D., Zhang, H., Song, J., et al. (2024). "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning". arXiv:2501.12948